Op 6 november 2023 maakte de overheid iets groots bekend: Nederland krijgt een eigen taalmodel! TNO werkt hieraan samen met het Nederlands Forensisch Instituut (NFI) en ICT-coöperatie SURF. En het ministerie van Economische Zaken gooide er een flinke zak geld tegenaan: 13,5 miljoen euro. Maar bijna 1 jaar later, en er is nog steeds geen model te bekennen. Volgens de planning wordt het model nu getraind maar waarschijnlijk zal het toch niet worden gebruikt.
Het idee van een taalmodel dat specifiek is getraind op Nederlandse data klinkt goed. Betere taalherkenning, nauwkeurigere vertalingen, en diepere analyses. Maar door zich alleen op Nederlandse data te richten, beperkt het model zichzelf. Het zal nooit zo veelzijdig zijn als de modellen van grote spelers zoals OpenAI, Anthropic of Meta. En daardoor zal het waarschijnlijk ook minder gebruikt worden. Zonde.
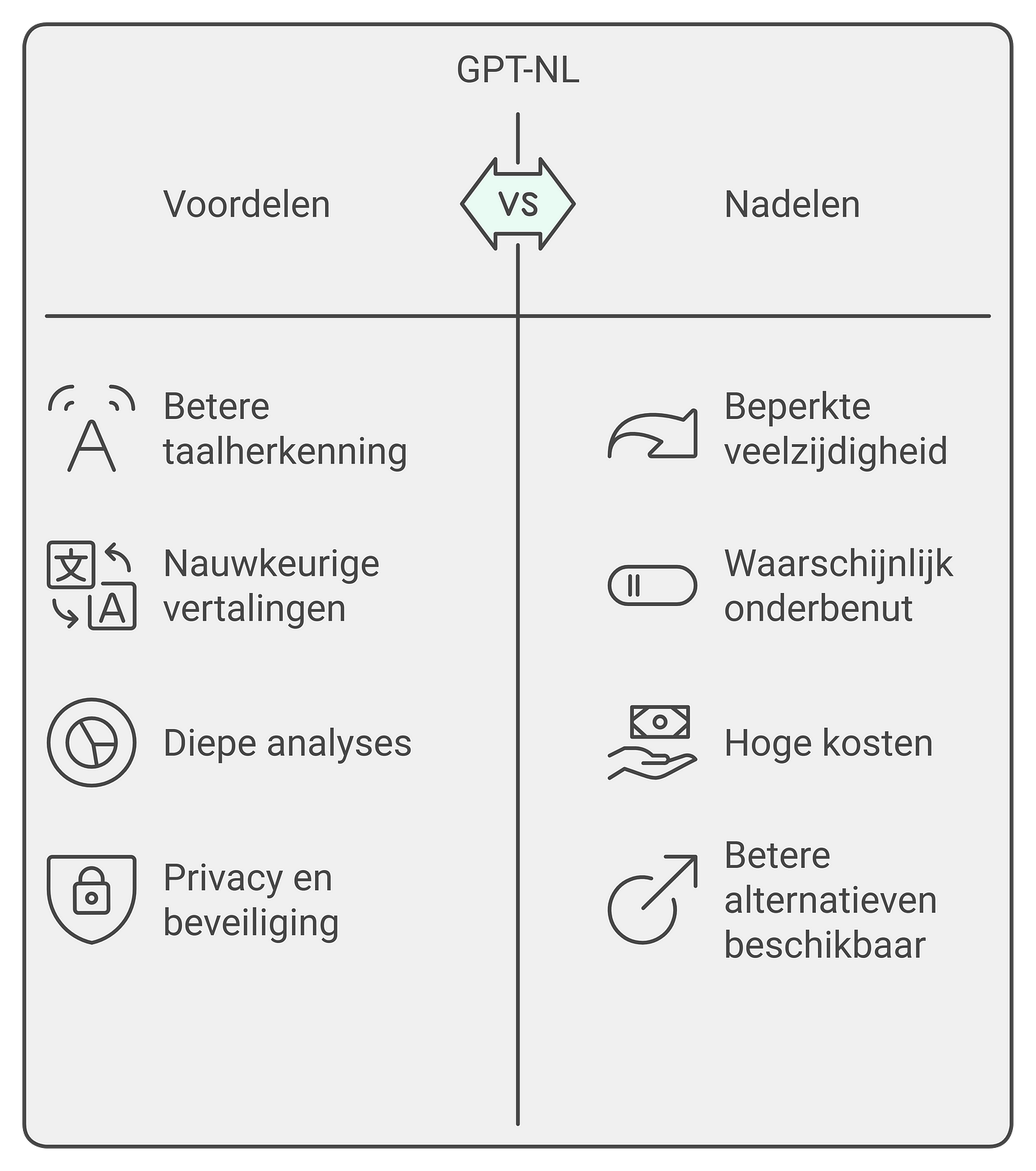
Zoals ik al eerder aanhaalde zijn Open-source modellen superbelangrijk. Waarom? Omdat ze bedrijven in staat stellen om hun data binnenshuis te houden. Dit is geweldig voor de privacy en beveiliging. Alleen zijn de huidige open-source modellen zoals LLama 3.2 gewoon slecht in Nederlands. Dit maakt de behoefte aan een goed functionerend Nederlands taalmodel des te groter.
Dus waarom finetunen we niet bestaande open-source modellen zoals de Llama modellen van Meta voor specifiek Nederlands gebruik? Dit zou Nederlandse bedrijven en instanties toegang geven tot een krachtig taalmodel dat kan concurreren met de grote namen. En het mooiste van alles? Het zou die investering van 13,5 miljoen euro een stuk rechtvaardiger maken.
Wat denk jij? Is GPT-NL weggegooid geld, of is er nog hoop voor dit ambitieuze project?
Goede analyse, helemaal mee eens!